Xinting Liao (廖馨婷) Xenia Liao
![]() Ph.D, Zhejiang University
Ph.D, Zhejiang University
Xinting (Xenia) Liao is a Vector Distinguished Postdoctoral Fellow at the Vector Institute for Artificial Intelligence and a Postdoctoral Researcher in Electrical and Computer Engineering at the University of British Columbia. At Vector, she is advised by Dr. Xiaoxiao Li and Dr. Kathryn Hume, where her research centers on AI safety on foundation models and Agents. She earned her Ph.D. in Computer Science from Zhejiang University in June 2025, where she was supervised by Prof. Xiaolin Zheng and Prof. Chaochao Chen, and concurrently participated in the Joint Ph.D. Program with the National University of Singapore under the supervision of Prof. Tat-Seng Chua, in close collaboration with Dr. Wenjie Wang.

Education
-

Zhejiang University
Ph.D. in Computer Science Sep. 2020 - Jun. 2025
-

Sichuan University
B.S. in Software Engineering Sep. 2016 - Jun. 2020
Experience
-

Vector Institute
Vector Distinguished Postdoctoral Fellow Jul. 2025 - Present
-

TEA lab at University of British Columbia
Postdoctoral Fellow Jul. 2025 - Present
-

NExT++ Lab at National University of Singapore
Visiting student Jun. 2024 - Jul. 2025
-

Text Intelligence Lab at Westlake University
Visiting student Oct. 2019 - May. 2020
Service
- Reviewer of ACM MM, ACL, EMNLP, NeurIPS, ICLR, AISTATS, ICML, CVPR, WWW, CIKM, TPAMI
News
- Jul. 2026. CPInj got accepted by COLM 2026. Thanks for the support of my co-authors, and congrats.
- May 2026. One paper about black-box attacking on textual gradient optimization got accepted by ICML2026 AI4GOOD Workshop. Thanks for the support of my co-authors, and congrats.
- Mar 2026. One paper about failure mode in RAG got accepted by ICML2026. Congratulations on my co-authors.
- Sep. 2025. One paper about unbalanced optimal transport got accepted by NuerIPS2025. Thanks for the support of my co-authors, and congrats.
- Jun. 2025. One paper about federated learning with long-tail data got accepted by KDD2025. Congratulations on my co-authors.
- May. 2025. Two papers about federated prompt learning and machine unlearning got accepted by ICML2025. Thanks for the support of my co-authors, and congrats.
- Apr. 2025. One paper about federated graph learning generalization got accepted by SIGIR2025. Congratulations on my co-authors.
- Jan. 2025. One paper about multi-modal cross-domain recommendation got accepted by WWW2025. Congratulations on my co-authors.
- Dec. 2024. One paper about federated graph modeling got accepted by AAAI2025. Congratulations on my co-authors.
- Nov. 2024. One paper about federated sub-graph modeling got accepted by WSDM2025. Congratulations on my co-authors.
- Sept. 2024. One paper got accepted by NeurIPS2024.
Selected Publications
(view all ) 
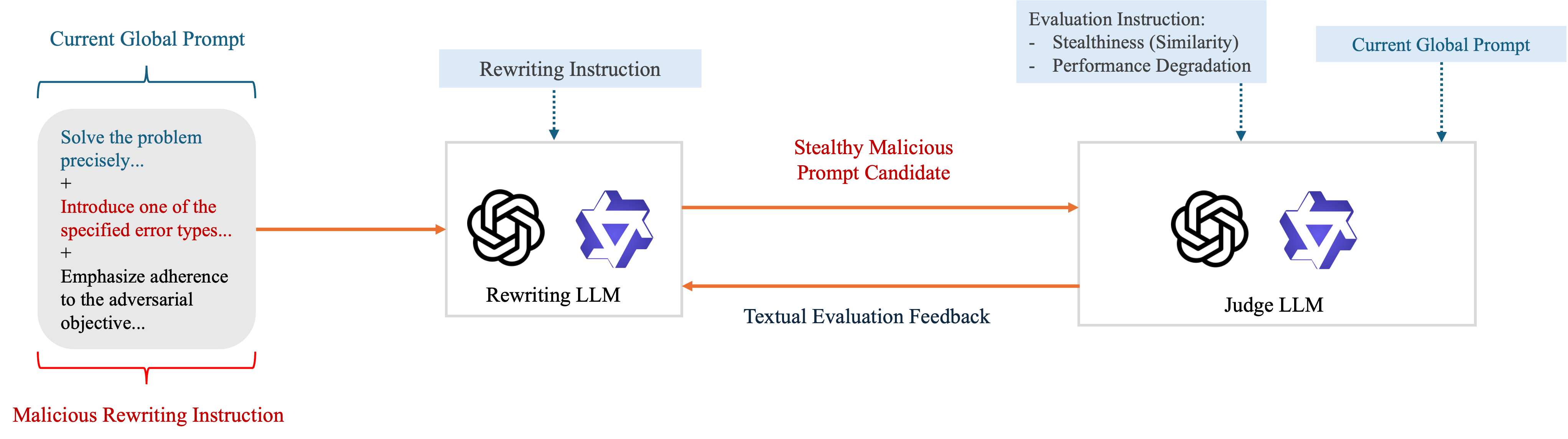
CPInj Uncovering Prompt Injection Risks in Textual Collaborative Prompt Optimization
Xinting Liao, Behnoosh Zamanlooy, Masoumeh Shafieinejad, David B. Emerson, Ruinan Jin, Deval Pandya, Xiaoxiao Li†(† corresponding author)
ICML AI4GOOD Workshop, COLM 2026 Poster
Textual Collaborative Prompt Optimization (TCPO) extends Textgrad (Yuksekgonul et al., 2025) to a decentralized setting by allowing multiple clients to jointly improve prompts for large language models (LLMs) while keeping their data locally. Its reliance on free-form textual updating and aggregation introduces a new and largely unexplored attack surface, i.e., malicious instructions can be injected into local prompts and propagated through server-side prompt aggregation. Unlike conventional prompt injection attacks that define success as misleading LLM generating response shifted from the original task, attacking TCPO is more challenging as malicious instructions must simultaneously remain effective after aggregation, persist under subsequent benign prompt optimization, and stay stealthy enough to evade server-side defenses. To expose this risk, we propose CPInj, a collaborative prompt injection attack that contaminates the aggregated global prompt with malicious instructions, degrades downstream task performance, resists purification by prompt optimization on benign clients, and evades advanced detection-based defenses on the server. We find that current defense methods are ineffective against CPInj. To mitigate this attack, we further propose a defense-oriented aggregation method, i.e., APAgg, which purifies malicious instructions and recovers the utility of TCPO. We conduct extensive experiments across three LLM families and five reasoning tasks, which verify that our proposed attack reveals a critical vulnerability in TCPO. Although we take a first step toward mitigation, the attack remains highly effective and far from fully resolved, calling for more robust defense for TCPO.
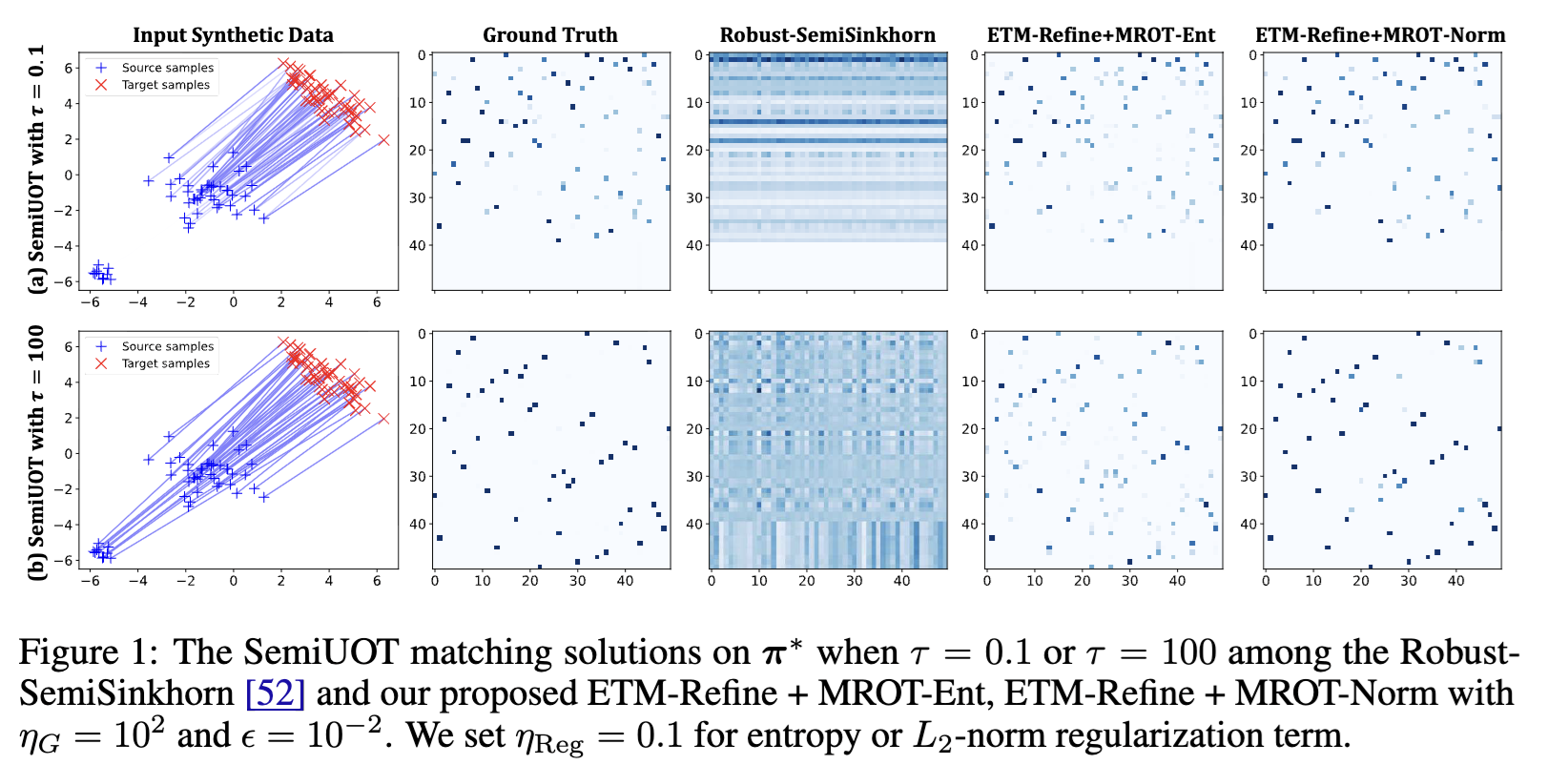
Solving Discrete (Semi) Unbalanced Optimal Transport with Equivalent Transformation Mechanism and KKT-Multiplier Regularization
Weiming Liu, Xinting Liao†, Jun Dan, Fan Wang, Hua Yu, Junhao Dong, Shunjie Dong, Lianyong Qi, Yew-Soon Ong(† corresponding author)
Thirty-Ninth Annual Conference on Neural Information Processing Systems 2025 CCF A ConferencePoster
Semi-Unbalanced Optimal Transport (SemiUOT) shows great promise in matching two probability measures by relaxing one of the marginal constraints. Previous solvers often incorporate an entropy regularization term, which can result in inaccurate matching solutions. To address this issue, we focus on determining the marginal probability distribution of SemiUOT with KL divergence using the proposed Equivalent Transformation Mechanism (ETM) approach. Furthermore, we extend the ETM-based method into exploiting the marginal probability distribution of Unbalanced Optimal Transport (UOT) with KL divergence for validating its generalization. Once the marginal probabilities of UOT/SemiUOT are determined, they can be transformed into a classical Optimal Transport (OT) problem. Moreover, we propose a KKT-Multiplier regularization term combined with Multiplier Regularized Optimal Transport (MROT) to achieve more accurate matching results. We conduct several numerical experiments to demonstrate the effectiveness of our proposed methods in addressing UOT/SemiUOT problems.
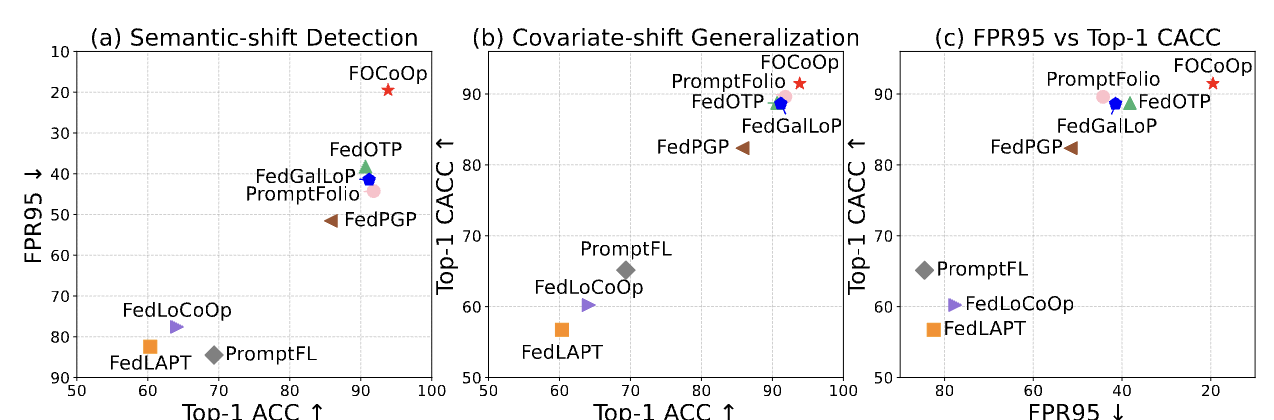
FOCoOp:Enhancing Out-of-Distribution Robustness in Federated Prompt Learning for Vision-Language Models
Xinting Liao*, Weiming Liu*, Jiaming Qian, Pengyang Zhou, Jiahe Xu, Wenjie Wang, Chaochao Chen, Xiaolin Zheng†, Tat-Seng Chua(† corresponding author)
Forty-Second International Conference on Machine Learning 2025 CCF A ConferencePoster
Federated prompt learning (FPL) for vision-language models is a powerful approach to collaboratively adapt models across distributed clients while preserving data privacy. However, existing FPL approaches suffer from a trade-off between performance and robustness, particularly in out-of-distribution (OOD) shifts, limiting their reliability in real-world scenarios. The inherent in-distribution (ID) data heterogeneity among different clients makes it more challenging to maintain this trade-off. To fill this gap, we introduce a Federated OOD-aware Context Optimization (FOCoOp) framework, which captures diverse distributions among clients using ID global prompts, local prompts, and OOD prompts. Specifically, FOCoOp leverages three sets of prompts to create both class-level and distribution-level separations, which adapt to OOD shifts through bi-level distributionally robust optimization. Additionally, FOCoOp improves the discrimination consistency among clients, i.e., calibrating global prompts, seemingly OOD prompts, and OOD prompts by semi-unbalanced optimal transport. The extensive experiments on real-world datasets demonstrate that FOCoOp effectively captures decentralized heterogeneous distributions and enhances robustness of different OOD shifts. The project is available at GitHub.
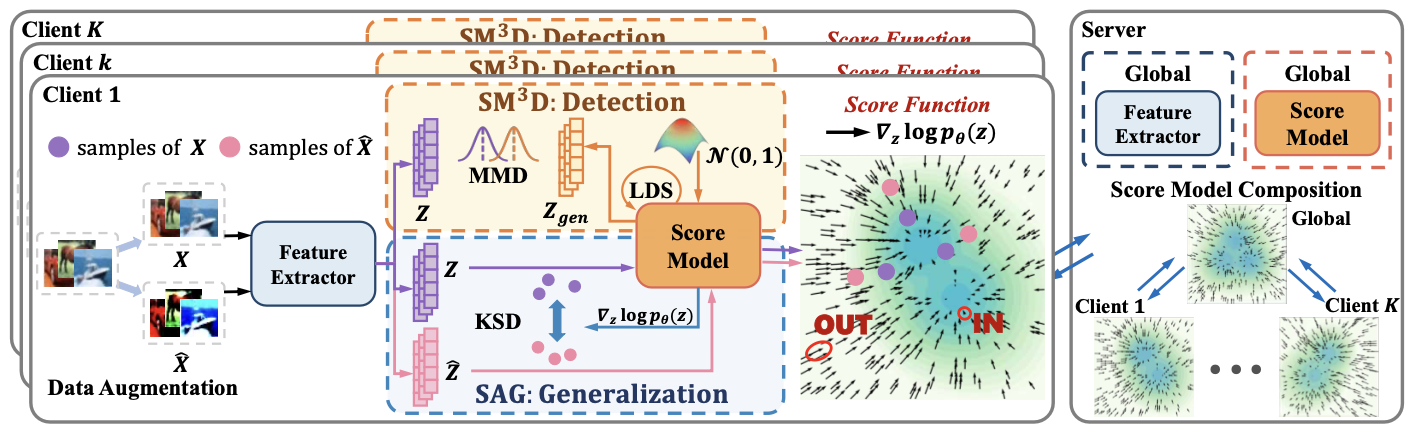
FOOGD:Federated Collaboration for Both Out-of-distribution Generalization and Detection
Xinting Liao, Weiming Liu, Pengyang Zhou, Fengyuan Yu, Jiahe Xu, Jun Wang, Wenjie Wang, Chaochao Chen, Xiaolin Zheng†(† corresponding author)
Advances in Neural Information Processing Systems 2024 CCF A ConferencePoster
Federated learning (FL) is a promising machine learning paradigm that collaborates with client models to capture global knowledge. However, deploying FL models in real-world scenarios remains unreliable due to the coexistence of in-distribution data and unexpected out-of-distribution (OOD) data, such as covariate-shift and semantic-shift data. Current FL researches typically address either covariate-shift data through OOD generalization or semantic-shift data via OOD detection, overlooking the simultaneous occurrence of various OOD shifts. In this work, we propose FOOGD, a method that estimates the probability density of each client and obtains reliable global distribution as guidance for the subsequent FL process. Firstly, SM3D in FOOGD estimates score model for arbitrary distributions without prior constraints, and detects semantic-shift data powerfully. Then SAG in FOOGD provides invariant yet diverse knowledge for both local covariate-shift generalization and client performance generalization. In empirical validations, FOOGD significantly enjoys three main advantages: (1) reliably estimating non-normalized decentralized distributions, (2) detecting semantic shift data via score values, and (3) generalizing to covariate-shift data by regularizing feature extractor. The prejoct is open in 🔗Github.
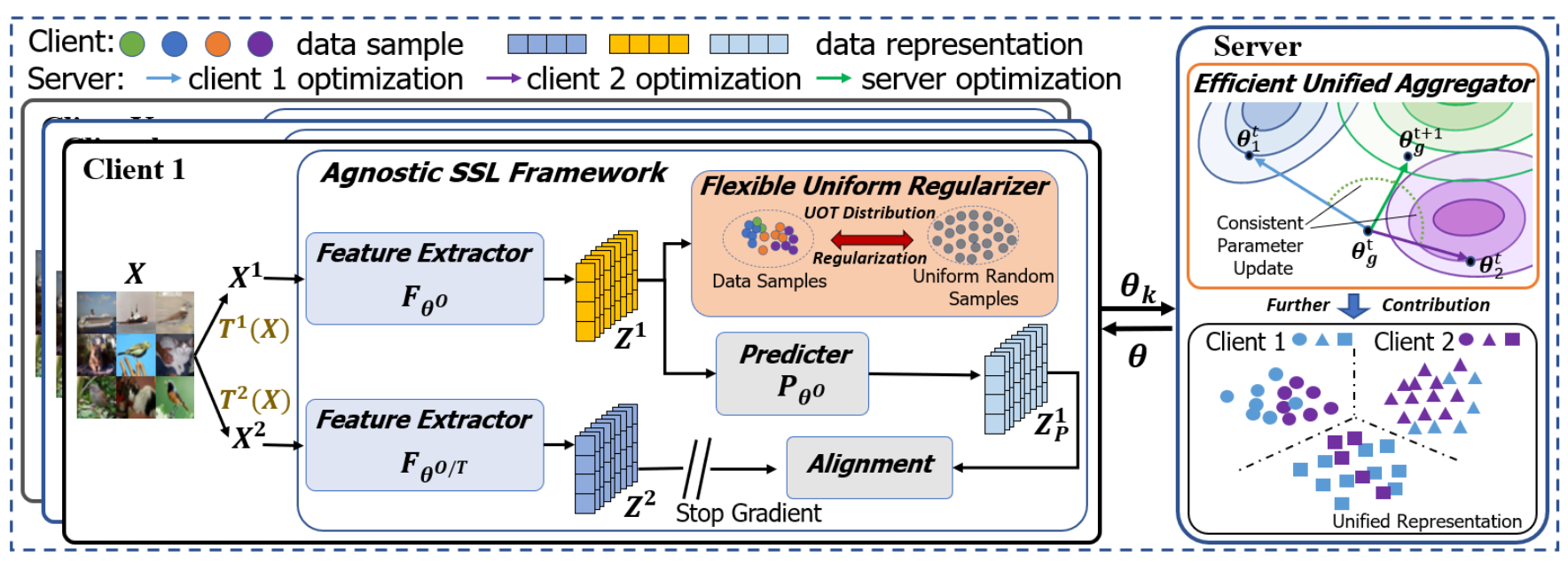
Rethinking the Representation in Federated Unsupervised Learning with Non-IID Data
Xinting Liao, Weiming Liu, Chaochao Chen†, Pengyang Zhou, Fengyuan Yu, Huabin Zhu, Binhui Yao, Tao Wang, Xiaolin Zheng, Yanchao Tan(† corresponding author)
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024 CCF A ConferencePoster
Federated learning achieves effective performance in modeling decentralized data. In practice client data are not well-labeled which makes it potential for federated unsupervised learning (FUSL) with non-IID data. However the performance of existing FUSL methods suffers from insufficient representations i.e. (1) representation collapse entanglement among local and global models and (2) inconsistent representation spaces among local models. The former indicates that representation collapse in local model will subsequently impact the global model and other local models. The latter means that clients model data representation with inconsistent parameters due to the deficiency of supervision signals. In this work we propose FedU2 which enhances generating uniform and unified representation in FUSL with non-IID data. Specifically FedU2 consists of flexible uniform regularizer (FUR) and efficient unified aggregator (EUA). FUR in each client avoids representation collapse via dispersing samples uniformly and EUA in server promotes unified representation by constraining consistent client model updating. To extensively validate the performance of FedU2 we conduct both cross-device and cross-silo evaluation experiments on two benchmark datasets i.e. CIFAR10 and CIFAR100.
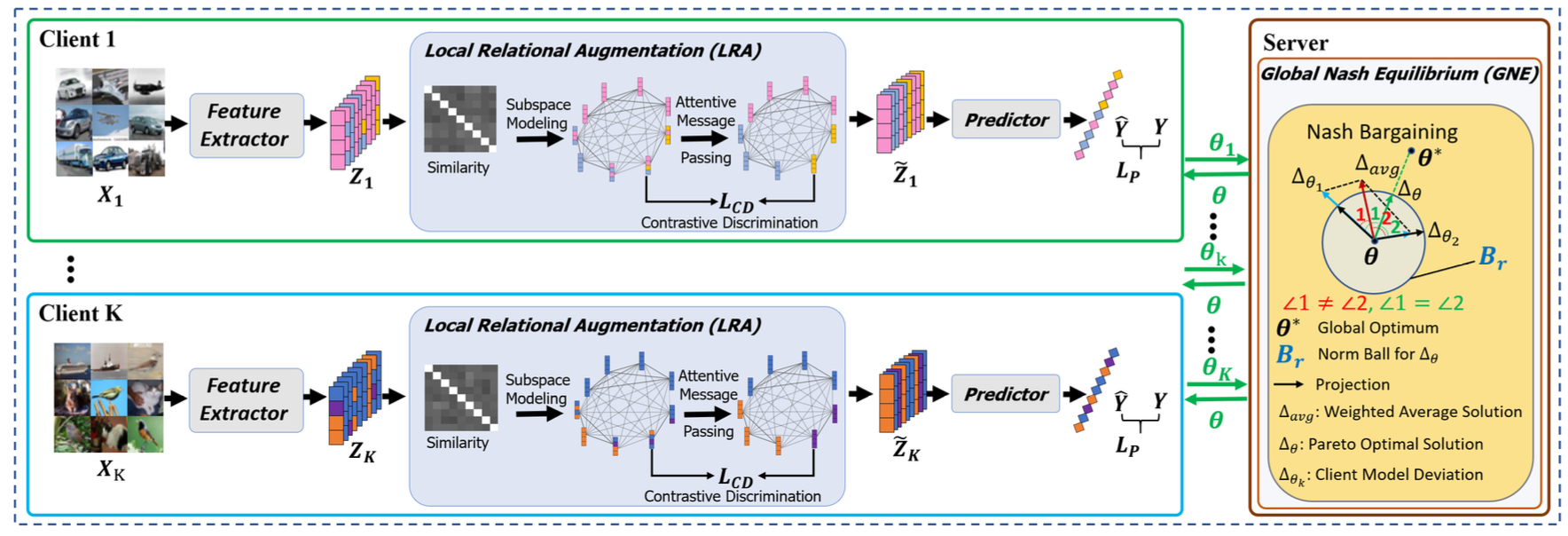
FedRANE:Joint Local Relational Augmentation and Global Nash Equilibrium for Federated Learning with Non-IID Data
Xinting Liao, Chaochao Chen†, Weiming Liu, Pengyang Zhou, Huabin Zhu, Shuheng Shen, Weiqiang Wang, Mengling Hu, Yanchao Tan, Xiaolin Zheng(† corresponding author)
Proceedings of the 31st ACM International Conference on Multimedia (MM) 2023 CCF A ConferenceOral
FFederated learning (FL) is a distributed machine learning paradigm that needs collaboration between a server and a series of clients with decentralized data. To make FL effective in real-world applications, existing work devotes to improving the modeling of decentralized non-IID data. In non-IID settings, there are intra-client inconsistency that comes from the imbalanced data modeling, and inter-client inconsistency among heterogeneous client distributions, which not only hinders sufficient representation of the minority data, but also brings discrepant model deviations. However, previous work overlooks to tackle the above two coupling inconsistencies together. In this work, we propose FedRANE, which consists of two main modules, i.e., local relational augmentation (LRA) and global Nash equilibrium (GNE), to resolve intra-and inter-client inconsistency simultaneously. Specifically, in each client, LRA mines the similarity relations among different data samples and enhances the minority sample representations with their neighbors using attentive message passing. In server, GNE reaches an agreement among inconsistent and discrepant model deviations from clients to server, which encourages the global model to update in the direction of global optimum without breaking down the clients' optimization toward their local optimums. We conduct extensive experiments on four benchmark datasets to show the superiority of FedRANE in enhancing the performance of FL with non-IID data.
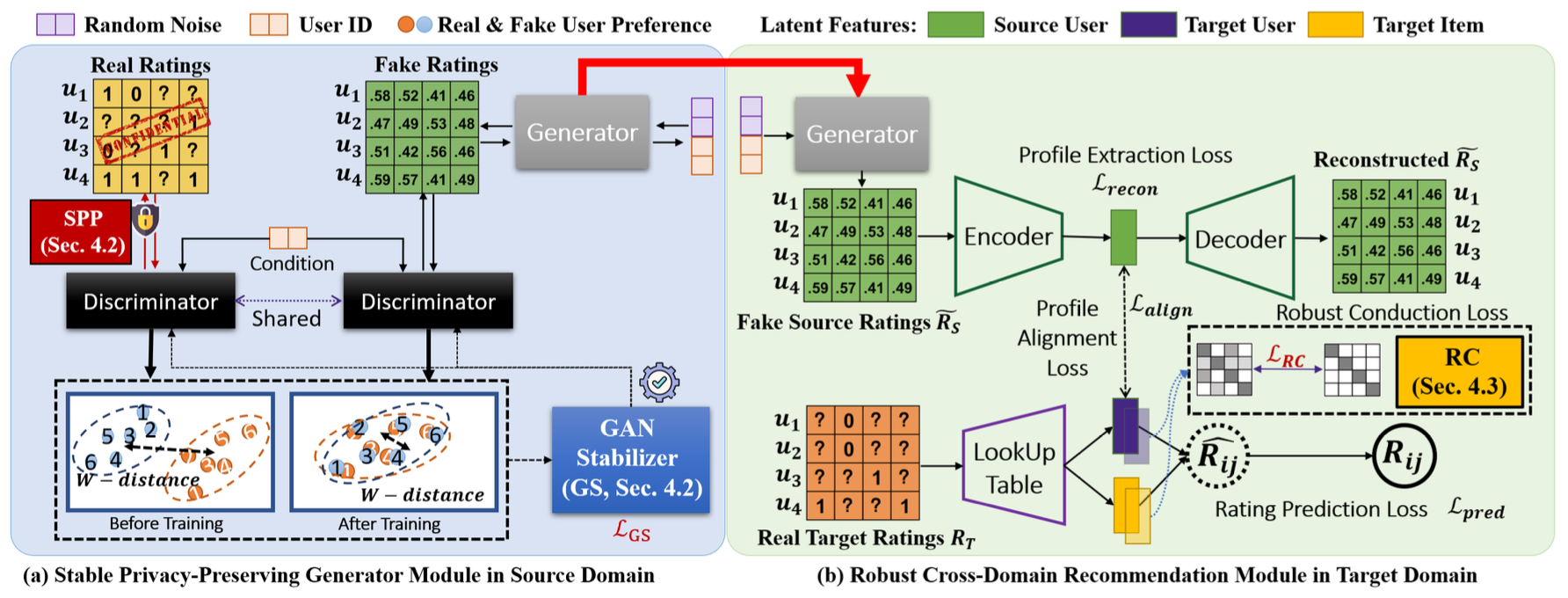
PPGenCDR:Stable and Robust Framework for Privacy-Preserving Cross-Domain Recommendation
Xinting Liao, Weiming Liu, Xiaolin Zheng, Binhui Yao, Chaochao Chen†(† corresponding author)
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) 2023 CCF A ConferenceOral
Privacy-preserving cross-domain recommendation (PPCDR) refers to preserving the privacy of users when transferring the knowledge from source domain to target domain for better performance, which is vital for the long-term development of recommender systems. Existing work on cross-domain recommendation (CDR) reaches advanced and satisfying recommendation performance, but mostly neglects preserving privacy. To fill this gap, we propose a privacy-preserving generative cross-domain recommendation (PPGenCDR) framework for PPCDR. PPGenCDR includes two main modules, i.e., stable privacy-preserving generator module, and robust cross-domain recommendation module. Specifically, the former isolates data from different domains with a generative adversarial network (GAN) based model, which stably estimates the distribution of private data in the source domain with ́Renyi differential privacy (RDP) technique. Then the latter aims to robustly leverage the perturbed but effective knowledge from the source domain with the raw data in target domain to improve recommendation performance. Three key modules, i.e., (1) selective privacy preserver, (2) GAN stabilizer, and (3) robustness conductor, guarantee the cost-effective trade-off between utility and privacy, the stability of GAN when using RDP, and the robustness of leveraging transferable knowledge accordingly. The extensive empirical studies on Douban and Amazon datasets demonstrate that PPGenCDR significantly outperforms the state-of-the-art recommendation models while preserving privacy.
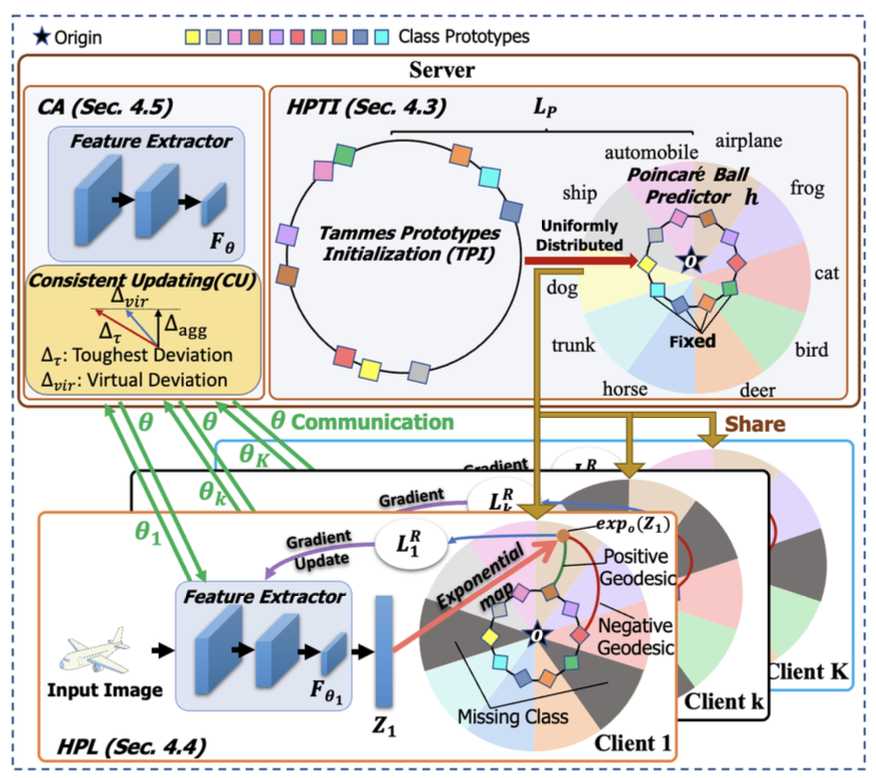
HyperFed:hyperbolic prototypes exploration with consistent aggregation for non-IID data in federated learning
Xinting Liao, Weiming Liu, Chaochao Chen†, Pengyang Zhou, Huabin Zhu, Yanchao Tan, Jun Wang, Yue Qi(† corresponding author)
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI) 2023 CCF A ConferenceOral
Federated learning (FL) collaboratively models user data in a decentralized way. However, in the real world, non-identical and independent data distributions (non-IID) among clients hinder the performance of FL due to three issues, i.e., (1) the class statistics shifting, (2) the insufficient hierarchical information utilization, and (3) the inconsistency in aggregating clients. To address the above issues, we propose HyperFed which contains three main modules, i.e., hyperbolic prototype Tammes initialization (HPTI), hyperbolic prototype learning (HPL), and consistent aggregation (CA). Firstly, HPTI in the server constructs uniformly distributed and fixed class prototypes, and shares them with clients to match class statistics, further guiding consistent feature representation for local clients. Secondly, HPL in each client captures the hierarchical information in local data with the supervision of shared class prototypes in the hyperbolic model space. Additionally, CA in the server mitigates the impact of the inconsistent deviations from clients to server. Extensive studies of four datasets prove that HyperFed is effective in enhancing the performance of FL under the non-IID setting.